On Mon, 2006-03-13 at 16:14 +0100, Michael Haardt wrote:
> You are right, RFC 2822 does not tell how clients should behave,
> meaning it simply does not answer the question.
>
> So, how should clients behave? :-)
My answer would be that they should preserve as much information in its
original form as possible. Make no changes which aren't necessary.
> Everybody agreed that line breaks in headers do not carry any semantic
> content, because agents may re-fold unstructured headers to their taste,
> and in fact do. You can not rely on line breaks to be preserved where
> they are.
It's email. Of _course_ you can't rely on any of it to be preserved,
even if it gets through at all. Just as you can't _rely_ on PGP
signatures to make it through intact, because weird stuff might happen
-- especially if interim mailers violate the principle of minimal
munging and decide to mess around with 'syntactically equivalent'
changes for no good reason.
Nevertheless, you can optimise for the sane case, and lay out your
headers (and indeed the rest of your mail) so that they're easy to read
in a mail client which doesn't screw with them.
> Does displaying semantically useless information make sense? That's the
> point where no consensus could be reached in the past. Perhaps that's
> why RFC 2822 does not even mention the topic.
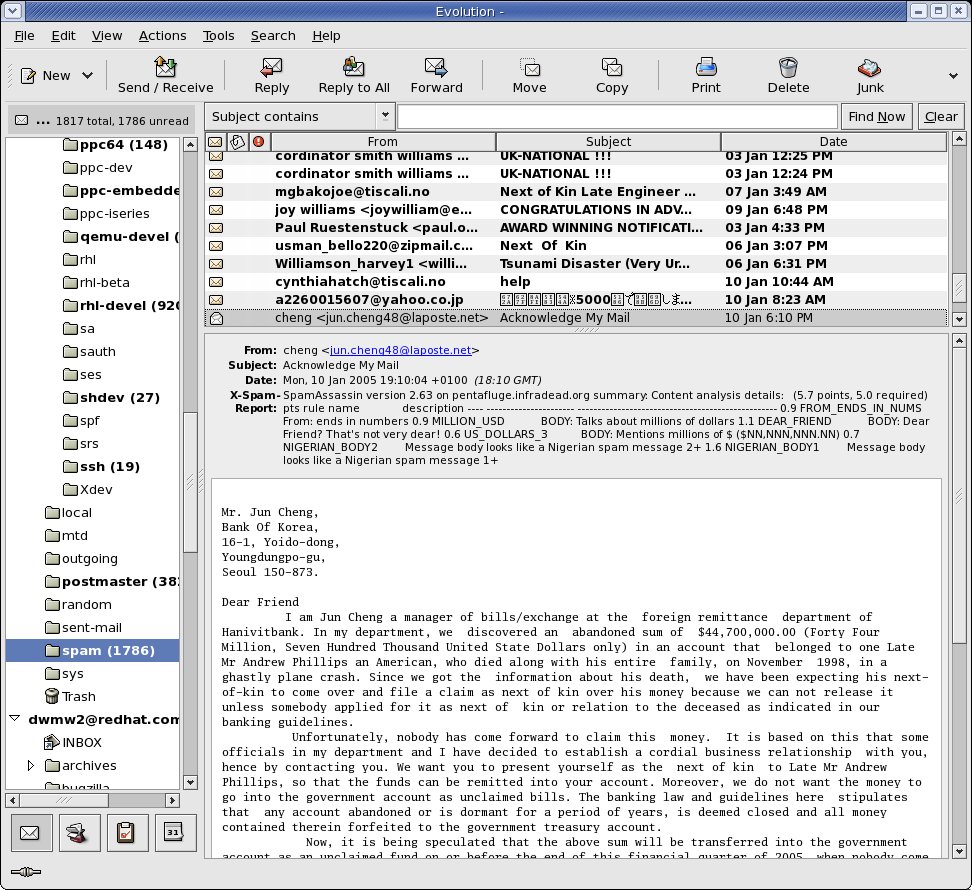
To pick a specific example of 'semantically useless information', let's
look again at
http://david.woodhou.se/evo-ate-my-spam-report.jpeg
My answer to your question would be a resounding 'yes'. It _does_ make
sense to display it as it was sent. There was often a _reason_ it was
sent the way it was. Even RFC2822 hints at this (§2.2.3 again):
Note: Though structured field bodies are defined in such a way that
folding can take place between many of the lexical tokens (and even
within some of the lexical tokens), folding SHOULD be limited to
placing the CRLF at higher-level syntactic breaks. For instance, if
a field body is defined as comma-separated values, it is recommended
that folding occur after the comma separating the structured items in
preference to other places where the field could be folded, even if
it is allowed elsewhere.
Think about it... why would it suggest that you wrap at 'higher-level
syntactic breaks' if it's expected that the receiving MUA is going to
disregard the line breaks anyway?
Let's ask the converse question -- why would it make sense to tamper
with it?
I can see the justification for fixing up MIME headers which are
actually broken, in an attempt to deal with the mail as its sender
_presumably_ intended it to be received. But to mangle whitespace for no
better reason than 'because we think we can' would be bizarre.
--
dwmw2




%0A>%20%0A>%20My%20answer%20would%20be%20that%20they%20should%20preserve%20as%20much%20information%20in%20its%0A>%20original%20form%20as%20possible.%20Make%20no%20changes%20which%20aren't%20necessary.%0A>%20%0A>%20>%20Everybody%20agreed%20that%20line%20breaks%20in%20headers%20do%20not%20carry%20any%20semantic%0A>%20>%20content,%20because%20agents%20may%20re-fold%20unstructured%20headers%20to%20their%20taste,%0A>%20>%20and%20in%20fact%20do.%20%20You%20can%20not%20rely%20on%20line%20breaks%20to%20be%20preserved%20where%0A>%20>%20they%20are.%0A>%20%0A>%20It's%20email.%20Of%20_course_%20you%20can't%20rely%20on%20any%20of%20it%20to%20be%20preserved,%0A>%20even%20if%20it%20gets%20through%20at%20all.%20Just%20as%20you%20can't%20_rely_%20on%20PGP%0A>%20signatures%20to%20make%20it%20through%20intact,%20because%20weird%20stuff%20might%20happen%0A>%20--%20especially%20if%20interim%20mailers%20violate%20the%20principle%20of%20minimal%0A>%20munging%20and%20decide%20to%20mess%20around%20with%20'syntactically%20equivalent'%0A>%20changes%20for%20no%20good%20reason.%0A>%20%0A>%20Nevertheless,%20you%20can%20optimise%20for%20the%20sane%20case,%20and%20lay%20out%20your%0A>%20headers%20(and%20indeed%20the%20rest%20of%20your%20mail)%20so%20that%20they're%20easy%20to%20read%0A>%20in%20a%20mail%20client%20which%20doesn't%20screw%20with%20them.%0A>%20%0A>%20>%20Does%20displaying%20semantically%20useless%20information%20make%20sense?%20That's%20the%0A>%20>%20point%20where%20no%20consensus%20could%20be%20reached%20in%20the%20past.%20%20Perhaps%20that's%0A>%20>%20why%20RFC%202822%20does%20not%20even%20mention%20the%20topic.%0A>%20%0A>%20To%20pick%20a%20specific%20example%20of%20'semantically%20useless%20information',%20let's%0A>%20look%20again%20at%20http://david.woodhou.se/evo-ate-my-spam-report.jpeg%0A>%20%0A>%20My%20answer%20to%20your%20question%20would%20be%20a%20resounding%20'yes'.%20It%20_does_%20make%0A>%20sense%20to%20display%20it%20as%20it%20was%20sent.%20There%20was%20often%20a%20_reason_%20it%20was%0A>%20sent%20the%20way%20it%20was.%20Even%20RFC2822%20hints%20at%20this%20(%C2%A72.2.3%20again):%0A>%20%0A>%20%20%20%20Note:%20Though%20structured%20field%20bodies%20are%20defined%20in%20such%20a%20way%20that%0A>%20%20%20%20folding%20can%20take%20place%20between%20many%20of%20the%20lexical%20tokens%20(and%20even%0A>%20%20%20%20within%20some%20of%20the%20lexical%20tokens),%20folding%20SHOULD%20be%20limited%20to%0A>%20%20%20%20placing%20the%20CRLF%20at%20higher-level%20syntactic%20breaks.%20%20For%20instance,%20if%0A>%20%20%20%20a%20field%20body%20is%20defined%20as%20comma-separated%20values,%20it%20is%20recommended%0A>%20%20%20%20that%20folding%20occur%20after%20the%20comma%20separating%20the%20structured%20items%20in%0A>%20%20%20%20preference%20to%20other%20places%20where%20the%20field%20could%20be%20folded,%20even%20if%0A>%20%20%20%20it%20is%20allowed%20elsewhere.%0A>%20%0A>%20Think%20about%20it...%20why%20would%20it%20suggest%20that%20you%20wrap%20at%20'higher-level%0A>%20syntactic%20breaks'%20if%20it's%20expected%20that%20the%20receiving%20MUA%20is%20going%20to%0A>%20disregard%20the%20line%20breaks%20anyway?%20%0A>%20%0A>%20Let's%20ask%20the%20converse%20question%20--%20why%20would%20it%20make%20sense%20to%20tamper%0A>%20with%20it?%0A>%20%0A>%20I%20can%20see%20the%20justification%20for%20fixing%20up%20MIME%20headers%20which%20are%0A>%20actually%20broken,%20in%20an%20attempt%20to%20deal%20with%20the%20mail%20as%20its%20sender%0A>%20_presumably_%20intended%20it%20to%20be%20received.%20But%20to%20mangle%20whitespace%20for%20no%0A>%20better%20reason%20than%20'because%20we%20think%20we%20can'%20would%20be%20bizarre.%0A>%20%0A>%20--%20%0A>%20dwmw2%0A>%20%0A>%20%0A>%20%0A>%20 "このメッセージに返信")
{kind=link}